チュートリアル
チュートリアルのセットアップにしたがって環境を構築してください。 バッチアプリケーションは、アプリケーションサーバが必要ありませんので、Seasarの設定をして、DBサーバを起動すれば完了です。 DBサーバの起動に関してはH2_Database_Engineの起動等を参考にしてください。
hello world
まずは、hello worldアプリケーションを作成してみましょう。
Collectorの作成
bathroyフレームワークを利用してバッチアプリケーションを作成する際は、Collectorというクラスを作成します。 このクラスは、データを取得するためのクラスです。 以下の制約にしたがって作成してください。
- ${rootPackage}/collectorパッケージ以下に作成してください。
- org.seasar.bathory.engine.Collectorを実装してください。
- クラス名をCollectorで終わらせてください。
package examples.bathory.collector;
import java.util.HashMap;
import java.util.Map;
import org.seasar.bathory.engine.Casket;
import org.seasar.bathory.engine.Collector;
public class HelloWorldCollector implements Collector {
@Override
public void collect(final Casket casket) {
Map value = new HashMap();
value.put("sysout", "hello world!");
casket.put(value);
}
}
Collectorは、データを収集することが目的のクラスなので、Casketへデータを1件格納しています。
Consumerの作成
次に、収集したデータを処理するクラスを作成します。 bathoryフレームワークでは、このようなクラスのことをConsumerと呼んでいます。 以下の制約にしたがって作成してください。
- ${rootPackage}/consumerパッケージ以下に作成してください。
- org.seasar.bathory.engine.Consumerを実装してください。
- クラス名をConsumerで終わらせてください。
なお、CollectorとConsumerを紐付けるため、クラス名の前半部分は同一のものにしてください。
例)
AaaCollector
の場合は
AaaConsumer
今回の場合は、HellowWorldCollectorなので、HelloWorldConsumer
package examples.bathory.consumer;
import org.seasar.bathory.engine.Consumer;
public class HelloWorldConsumer implements Consumer {
public String sysout;
@Override
public void consume() {
System.out.println(sysout);
}
}
これで準備は完了です。
hello world実行
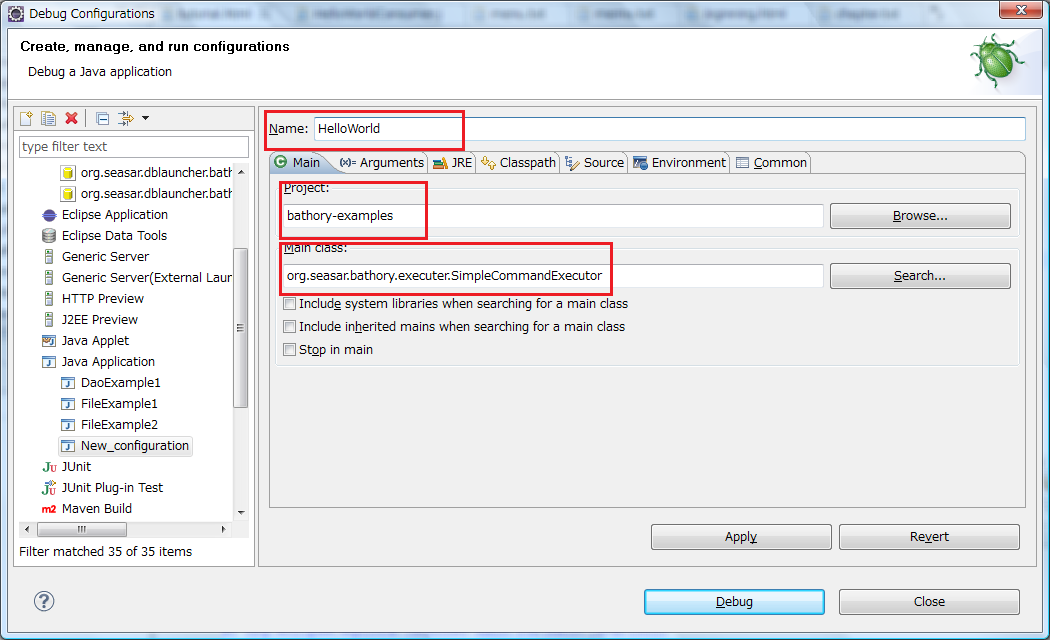
では、実行してみましょう。 Eclipseのメニュー[Run]=>[Debug Configurations...]=>Java Application=>New を選択して、Debugの構成を表示してください。
mainタブでは、以下の三点を設定してください。
- Name:何でもかまわないですが、有意な名称を付与してください。
- project:対象のプロジェクトを指定してください。
- Main class:"org.seasar.bathory.executer.SimpleCommandExecutor"を指定してください。
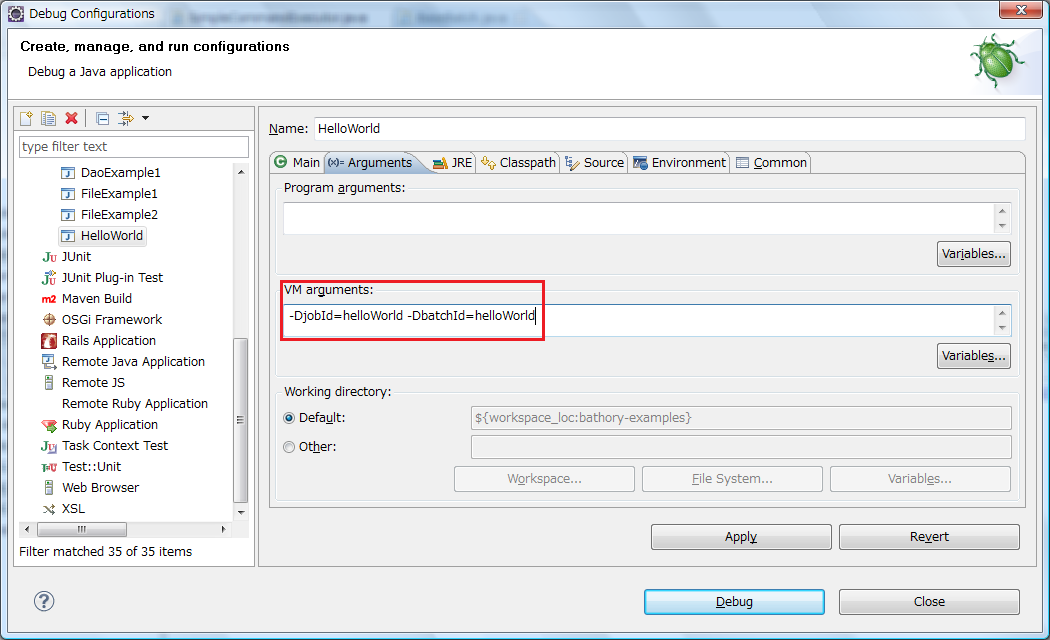
Argumentsタブでは、VM argumentsへ以下の二点を設定してください。
- jobId:何でもかまわないですが、有意な名称を付与してください。
- batchId:Collector,Consumerのクラス名共通部分を先頭小文字にした文字列を指定してください。(ここでは、helloWorld)
簡単に実行できましたね。
hello worldまとめ
ポイントは以下のとおりです。
- Collectorは、引数に渡されたCasketへデータをMap形式にしてデータを追加します。
- Consumerは、Casketに追加した名称のフィールドに値が格納され、consumeメソッドが呼び出されます。consumeメソッドには、仕様に応じた処理を記述します。
S2Daoを使用した例
S2Daoを利用したサンプルを作成してみましょう。 Collectorは通常のオンラインアプリケーションと大きな差異があります。
Daoの作成
S2DaoにはFetchHandlerという機能があります。 この機能を利用します。
package examples.bathory.dao;
import org.seasar.bathory.extentions.s2dao.FetchHandlerAdapter;
import org.seasar.dao.annotation.tiger.Arguments;
import org.seasar.dao.annotation.tiger.SqlFile;
public interface S2DaoExample1Dao {
@SqlFile
@Arguments("targetDate")
public void selectRecentHistory(String date, FetchHandlerAdapter adapter);
}
SELECT * FROM emp WHERE hiredate > PARSEDATETIME(/*targetDate*/'19810131', 'yyyyMMdd')
メソッドの二番目にFetchHandlerAdapterを指定しているところがポイントです。
Collectorの作成
S2Daoを使用したCollectorは以下のようになります。
package examples.bathory.collector;
import org.seasar.bathory.engine.Casket;
import org.seasar.bathory.engine.Collector;
import org.seasar.bathory.extentions.s2dao.FetchHandlerAdapter;
import examples.bathory.dao.S2DaoExample1Dao;
public class S2DaoExample1Collector implements Collector {
public S2DaoExample1Dao dao;
@Override
public void collect(final Casket casket) {
String date = "19810131";
dao.selectRecentHistory(date, new FetchHandlerAdapter(casket));
}
}
メソッドの二番目にFetchHandlerAdapterを指定しているところ以外は通常のS2Daoを使用したアプリケーションと変わりありません。 この記述だけで内部的には以下のことを行います。
- 検索結果をMapに格納してcasketに引き渡す。
- 検索結果はcasketを通じてConsumerへ引き渡される。
Consumerの作成
Consumerでは、処理対象データ一件に対する業務処理を記述します。
package examples.bathory.consumer;
import java.math.BigDecimal;
import java.util.Date;
import java.util.Random;
import org.seasar.bathory.engine.Consumer;
import org.seasar.framework.beans.util.BeanUtil;
import examples.bathory.dao.EmpDao;
import examples.bathory.entity.Emp;
public class S2DaoExample1Consumer implements Consumer {
public Long id;
public Integer empNo;
public String empName;
public Integer mgrId;
public Date hiredate;
public BigDecimal sal;
public Integer deptId;
public Integer versionNo;
public EmpDao dao;
@Override
public void consume() {
// 自分自身に値が格納されているので、処理を行う。
Emp data = new Emp();
BeanUtil.copyProperties(this, data);
// 業務処理を記述していく
// 以下は仮想的な業務処理
int rand = new Random(System.currentTimeMillis()).nextInt(100);
if (rand % 5 == 0) {
// 減給もアリ
rand *= -1;
}
BigDecimal diff = BigDecimal.valueOf(rand);
data.sal = (data.sal.add(diff));
dao.update(data);
}
}
ConsumerはSAStrutsのActionやTeedaのPageクラスのように処理を記述してください。 もちろんServiceクラスやLogicクラスに処理を切り出しても問題ありません。
実行
先ほどと同様に、新たにDebug Configurationを作成して実行してください。
S2JDBCを使用した例
S2JDBCにはIterationCallbackという機能があります。 この機能を利用します。
TBD